
BPF(Berkeley Packet Filter)
BPF(Berkeley Packet Filter)는 Unix-like OS의 Kernel Level에서 Bytecode에 따라 동작하는
경량화된VM(Virtual Machine)입니다. BPF는 의미 그대로 처음에는 Network Packet을 Filtering하는 Program을 구동하는 용도의 VM이였습니다. 하지만 사용자가 원하는 기능을 수행하는 Program을 언제든지 Kernel Level에서 구동 할 수 있다는 BPF의 장점 때문에 BPF는 꾸준히 발전하였고, 현재는 다양한 기능을 수행하는 VM이 되었습니다. 현재 Linux에서 BPF를 지원하고 있습니다.
경량화된 VM(Virtual Machine)입니다. BPF는 의미 그대로 처음에는 Network Packet을 Filtering하는 Program을 구동하는 용도의 VM이였습니다. 하지만 사용자가 원하는 기능을 수행하는 Program을 언제든지 Kernel Level에서 구동 할 수 있다는 BPF의 장점 때문에 BPF는 꾸준히 발전하였고, 현재는 다양한 기능을 수행하는 VM이 되었습니다. 현재 Linux에서 BPF를 지원하고 있습니다.
eBPF(Extended Berkeley Packet Filter)
eBPF는 Kernel 내 VM(Virtual Machine)의 한 종류입니다.
bpf() system call을 통해서 user space와 eBPF Program이 통신할 수 있습니다.
Android에서는 부팅 시 eBPF 프로그램을 로드하여 커널 기능을 확장하는 eBPF 로더 및 라이브러리가 포함되어 있습니다. eBPF로더는 커널, 모니터링 또는 디버깅에서 통계를 수징하는데 사용할 수 있습니다.
eBPF 정보
eBPF는 사용자 제공 eBPF Program을 실행하는 Kernel 내 VM(Virtual Machine)입니다. 이러한 Program을 Kernel의 Probe나 Event에 연결하여 유용한 통계를 수집하고 결과를 분석, 저장할 수 있습니다.
Linux Kernel v3.18부터 eBPF란 기능이 생겼습니다. 유의미하게 쓸 수 있는 버전은 v.4.9 이후 부터 입니다. 또한 이를 고수준언어에서 활용하게해주는 BCC ToolKit이 있습니다.
eBPF는 x86-64와 arm64의 공통점을 따온 것 처럼 보이는 별도의 어셈블리 언어입니다. 실제로 이런 코드를 사람이 직접 작성 하지는 않습니다. 단지 성능 측정을 위한 C 언어 코드를 작성하면 이를 eBPF 프로그램으로 Transpile합니다. (BCC 툴체인의 기능)
여기서 Transpile이라 함은 한 언어로 작성된 소스코드를 비슷한 수준의 추상화(Abstraction)를 가진 다른 언어로 변환하는 것을 말합니다.
이 eBPF Program을 bpf() system call을 통해서 Linux Kernel에 전달하면 해당 내용을 Kernel 안의 Sandbox형태의 Interpreter(JVM 처럼 다른 프로그램을 실행시켜주는 VM)로 동작합니다. 다만 Kernel에서 돌릴 것이라 아래의 몇가지 검증을 합니다.
•
동작 중에 crash날 만한 코드가 있는지 확인합니다.
•
허용되지 않은 함수에 접근 하는지 확인합니다.
•
허용되지 않은 stack이나 memory 접근을 하는지 확인합니다. (직접 선언한 값이나 stack으로 넘어온 값에 대하여 참조하는 일부 값만 접근가능합니다.)
•
데이터는 미리 선언한 일종의 해시맵에만 저장할 수 있습니다
이를 통해 eBPF Program은 아래와 같은 몇가지 데이터를 수집합니다.
•
system Call, 혹은 Kernel 내에서의 Function Call
•
user space(user program) 내의 Function Call
•
Program에서 정의한 Tracing 지점 (python 이나 JVM, node.js 같은 고수준 언어/프레임워크에서 주로 제공합니다.)
user space에서는 이미 동작 중인 eBPF Program과 통신해서 동작을 수정하거나(ex.. 측정 대상을 추가) 현재까지 수집된 데이터를 가져가거나 할 수 있습니다. 이 역시 bpf() system call을 통해서 이뤄집니다.

결국, bpf() system call을 통해서 user spcae와 eBPF Program이 통신이 가능하게 되는 것 입니다.
BCC(eBPF Compiler Collection)
eBPF는 성능 측정을 위한 기능을 제공합니다. 하지만 이를 위해서는 C 언어를 이용해서 Program을 짜고 데이터를 주고 받아야 합니다. 이런 복잡함을 줄이기 위해서 BCC를 이용합니다. BCC를 사용하면 아래와 같은 방법으로 성능 측정을 할 수 있습니다.
1.
C 언어로 성능 데이터 수집하는 코드 작성
2.
Python이나 go 혹은 lua로 1에서 작성한 데이터를 eBPF Program으로 생성합니다. 만약 필터링이 필요한 경우(특정 프로세스나 스레드로 제한하는 등) 1의 Program을 전송하기 전에 수정합니다.
3.
BCC Compile(1의 코드를 eBPF Program으로 변환) 후 Kernel에 Load
4.
eBPF Program 추가로 데이터 측정할 곳에 연결합니다.
이 과정을 마친 후에는 Kernel에 있는 eBPF Program과 user spcae에 있는 Program이 통신할 수 있습니다. 주기적으로 현재까지의 데이터를 가져와서 통계를 보여주거나 아니면 추가로 특정 데이터를 수집하거나 하는 일을 할 수 있습니다.
왜 유용한가?
eBPF 는 일정한 제약이 가해지기 때문에, 성능 측정 대상을 Crash하게 만들기 어렵습니다. 측정하는 데이터에 따라선 측정하는 동안 성능이 떨어질 순 있습니다. 또한 이 측정은 측정 대상에 해당하는 Program 수정이나 재시작이 필요하지 않기 때문에 실 서비스에서도 적용할 수 있고, 측정 부하도 매우 낮습니다. 모든 측정은 Kernel 안에서 이뤄집니다. 그리고 이 모든 과정이 측정 대상 외부에서 이뤄져서, 필요한 부분에 대해 측정 방법을 바꾸고, 수집할 데이터를 달리하면서 성능 문제를 추적할 수 있습니다.
즉, 아래와 같은 과정을 빠르게 반복할 수 있습니다:
1.
성능 문제에 대한 가설을 세웁니다.
2.
가설에 해당하는 측정 데이터를 찾고 eBPF + BCC Program으로 만듭니다.
3.
측정하고, 가설이 맞았는지 확인합니다. 틀렸다면 다시 범위를 좁히거나 다른 영역으로 넘어가서 1로.
cBPF(Classic BPF), eBPF(Extended BPF)
cBPF(Classic BPF), eBPF(Extended BPF)의 차이점

•
cBPF and eBPF Diff
위 그림은 cBPF(Classic BPF)와 eBPF(Extended BPF)를 나타내고 있습니다. BPF가 다양한 기능을 수행하면서 BPF가 갖고있는 매우 제한된 Resource는 큰 걸림돌이 되었습니다. 이러한 BPF의 Resource 문제를 해결하기 위해서 Linux는 더 많은 Resource와 기능을 이용할 수 있는 eBPF(Extened BPF)를 정의하였습니다. eBPF를 정의하면서 기존의 BPF는 cBPF(Classic BPF)라고 불립니다.
cBPF에서는 2개의 32bit Register와 메모리 역할을 수행하는 16개의 32bit Scratch Pad만을 이용 할 수 있었습니다. 하지만 eBPF에서는 11개의 64bit Register, 512개의 8bit Stack, Key-Value를 저장할 수 있는 무제한의 Map을 이용 할 수 있습니다.
또한 실행할 수 있는 Bytecode도 추가되어 eBPF에서는 Kernel이 eBPF 지원을 위해 제공하는 Kernel Helper Function을 호출하거나 다른 eBPF Program을 호출할 수 있습니다. 이처럼 eBPF는 cBPF보다 많은 Resource 및 기능을 이용 할 수 있기 때문에 cBPF보다 다양한 기능의 Program을 구동 할 수 있습니다.
cBPF(Classic BPF), eBPF(Extended BPF)의 지원
현재 Linux에서는 cBPF, eBPF 둘다 이용하고 있으며, BPF가 실행되는 지점인 Hook과 Kernel Version에 따라서 어떤 BPF가 이용될지 결정됩니다. bpf() System Call이 추가된 Kernel Version은 3.18인데, 3.18 이전 Version의 BPF는 모두 cBPF입니다. 예를들어 Socket() System Call의 SO_ATTACH_FILTER Option이나 Seccomp() System Call의 SECCOMP_SET_MODE_FILTER Option을 통해 이용하던 BPF는 모두 cBPF였습니다. 하지만 3.18 이후 Version에 추가된 BPF는 모두 eBPF입니다. eBPF가 도입되면서 cBPF는 현재 일부에서만 이용되고 있고 추후 eBPF가 cBPF를 완전히 대체하게될 예정입니다.
현재 Linux에서 Socket() System Call의 경우 eBPF를 이용하는 SO_ATTACH_BPF Option이 추가되었습니다. 물론 하위 호환성을 위해서 SO_ATTACH_FILTER Option도 여전히 제공합니다. 하지만 SO_ATTACH_FILTER Option을 이용하더라도 내부적으로는 bpf() System Call을 이용하여 cBPF Bytecode를 eBPF Bytecode를 변경한뒤 eBPF에 적재합니다. Seccomp() System Call의 경우에는 아직도 cBPF만을 지원하지만, 현재 eBPF 지원을 위한 개발이 진행중입니다.
eBPF Program Compile, bpf() System call

•
eBPF Program Compile, bpf() System Call
위 그림은 eBPF Program의 Compile 과정과 bpf() System Call의 동작을 나타내고 있습니다. LLVM/clang은 Backend로 eBPF를 지원합니다. 개발자가 작성한 eBPF Source Code는 LLVM/clang을 통해서 eBPF Bytecode로 Compile됩니다. 그 후 eBPF Bytecode는 tc나 iproute2같은 eBPF 관리 App(Tool)을 이용해 Kernel의 eBPF에 적재됩니다. eBPF 관리 App은 내부적으로 bpf() System Call을 이용하여 eBPF에 eBPF Bytecode를 적재합니다.
eBPF Bytecode는 Kernel Level에서 동작하기 때문에 잘못 작성된 eBPF Bytecode은 System 전체에 큰영향을 줄 수 있습니다. 따라서 Kernel은 eBPF Bytecode를 적재전에 Verifier로 eBPF Bytecode에 이상이 없는지 검사합니다. Verifier는 eBPF Bytecode가 허용되지 않은 Memory 영역을 참조하는지 검사하고, 무한 Loop가 발생하는지도 검사합니다. 또한 허용되지 않은 Kernel Helper Function을 호출했는지도 검사합니다. 검사를 통과못한 eBPF Bytecode는 적재에 실패합니다. 검사를 통과한 eBPF Bytecode는 eBPF에 적재되어 동작합니다. 필요에 따라 eBPF Bytecode의 일부는 JIT(Just-in-time) Compiler를 통해서 Native Code로 변환되어 Kernel에서 동작합니다.
bpf() System Call은 eBPF Bytecode 적재 뿐만 아니라 App이 eBPF가 이용하는 Map에 접근할 수 있게 만들어줍니다. 따라서 App과 eBPF는 Map을 이용하여 통신을 할 수 있습니다. eBPF와 App사이의 통신은 eBPF가 더욱 다양한 기능을 수행 할 수 있도록 만든다.
BPF Program Type
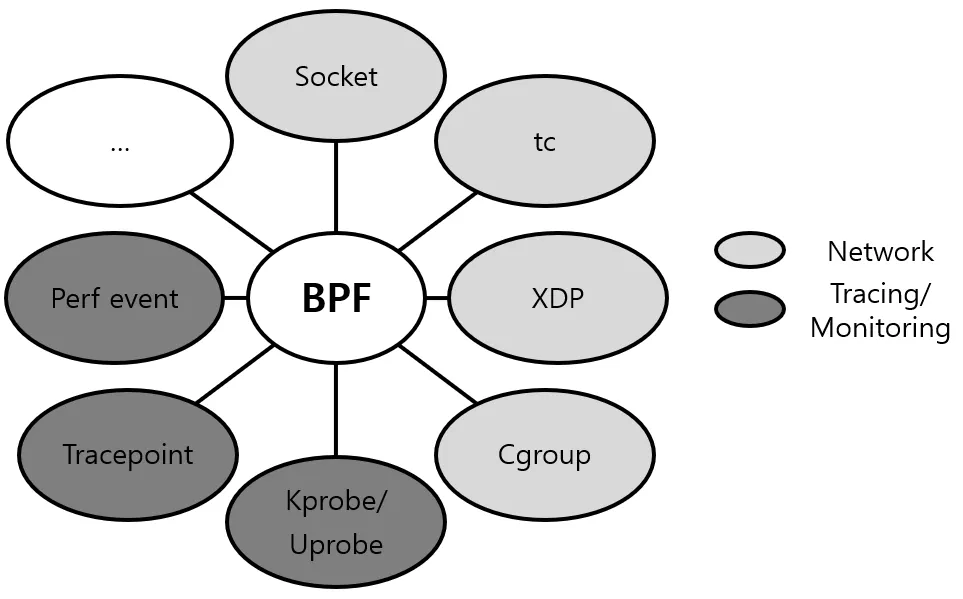
•
eBPF Program Type
BPF Program Type은 BPF Program이 실행될 수 있는 Hook을 결정합니다. 따라서 BPF Program Type은 BPF Program의 Input Type과 Input Data를 결정합니다. 또한 BPF Program Type은 BPF Program이 호출할 수 있는 Kernel Helper Function을 결정합니다. 위 그림은 eBPF Program Type을 나타내고 있습니다. 앞으로 Kernel에 더욱 많은 Hook이 추가되는 만큼 eBPF Program Type도 추가될 예정입니다.
eBPF 사용법


Container에 어떻게 eBPF를 적용할 것 인가?
Container 및 Kubernetes의 경우 Cilium 또는 Calico와 같은 Network project, BCC, kubectl-trace, Inspektor Gadget과 같은 Debuging Solutions과 Falco와 같은 보안 관련 프로젝트를 이용할 수 있습니다.
또한 sysdig는 eBPF를 활용하여 Host 및 Network Data, Container Process, Resource 활용등 Cloud 환경 및 Container 환경에 대한 분석 결과를 제공합니다.
Sysdig란
sysdig는 고성능 system call trace 프로그램입니다.
stateful filter, container 및 Lua 스크립팅에 매우 광범위한 user space 지원이 특징입니다. 또한 sysdig는 troubleshooting ecosystem에서 매우 Container 친화적으로 만들었습니다.
sysdig 인텔리전스가 user space에서 구현됩니다. 각 system call은 컨텍스트(ex: process metadata, container 및 orchestrator metadata, file/connection metadata, ...)를 각 개별 이벤트에 연결하는 status system을 거치며, 이 컨테스트는 필터링에 사용될 수 있습니다. 예를 들어, isolated된 write() sysdig를 trace하는 것만으로 sysdig는 참조하는 파일, network 연결, process 및 Docker Container를 알 수 있습니다.

•
sysdig 아키텍처
여기서 다시 한번 중요한 부분은 최신 버전의 Clang 및 LLVM을 사용하여 컴파일되며, C Code를 eBPF Byte Code로 변환합니다. sysdig를 이용하여 아래의 6가지 행위가 가능합니다.
1.
system call entry path
2.
system call exit path
3.
Process context switch
4.
Process termination
5.
Minor and major page faults
6.
Process signal delivery
각 프로그램은 실행 지점별 데이터(ex: system call, 프로세스 호출에서 전달한 인수)를 입력으로 받아 처리를 합니다. 여기서 하는 처리는 system call 유형에 따라 다릅니다. system call의 경우 인수는 전체 이벤트 프레임이 형성될 때까지 임시 저장에 사용되는 eBPF MAP에 그대로 복사됩니다. 다른 더 복잡한 호출의 경우 eBPF 프로그램에서는 인수를 변환하거나 추가하는 논리가 포함되며, 이런 것들을 통해서 user space의 sysdig application의 데이터를 완전히 활용할 수 있습니다. 이렇게 추가되는 데이터 중 일부는 아래의 3가지 정도 입니다.
1.
네트워크 연결과 관련된 데이터(ex: TCP/UDP IPv4/IPv6 Tuple, UNIX Socket Name등)
2.
Process에 대한 매우 세분화된 매트릭스(Memory Counters, Page Faults, Socket Queue Length 등)
3.
System call을 실행하는 Process가 속한 cgroup 및 Process가 있는 Namespace와 같은 컨테이터별 데이터.

•
sysdig eBPF 아키텍처
eBPF 프로그램이 수행할 수 있는 작업의 제한적인 특성으로 인해 이 정보 중 일부는 eBPF Code에서 쉽게 얻을 수 없습니다.
eBPF 프로그램이 특정 system call에 필요한 모든 데이터를 캡처하면 special native BPF 기능을 사용하여 sysdig user space application이 매우 높은 처리량으로 읽을 수 있는 CPU별 Ling Buffers set로 데이터를 푸시합니다. 이것이 sysdig에서 eBPF를 사용하는 것이 kernel space에서 생성된 "small data"를 user space와 공유하기 위해 eBPF MAP을 사용하는 일반적인 패러다임과 다른 점 입니다.
sysdig 아키텍처에서 eBPF MAP은 user space와 공유 목적으로 최소한으로 사용됩니다. 모든 데이터는 특정 사용 사례에 맞게 조정된 확장ㅆ 가능한 Ring Buffers를 통해 flows됩니다. 이를 통해 sysdig는 최소한의 overhead로 kernel에서 user space로 매우 많은 양의 데이터를 전송할 수 있습니다. 그런 다음 우리는 sysdig Process Memory에서 system status를 데이터를 활용할 수 있습니다.
또한 성능면에서 결과는 좋습니다.

•
System 별 OverHead
sysdig의 eBPF가 OverHead 측면에서 Kernel Moudle보다 약간 더 큰 것을 확인할 수 있습니다. 또한 직접 더 Filtering을 수행하여 sysdig가 OverHead를 적게 발생하도록 조정하는 것 또한 가능합니다.
사용법
eBPF와 함께 sysdig를 사용하는 것은 설계상 문제가 없으며 transparent합니다. 즉, eBPF를 지원하는 최신 Linux Kernel(4.14+)에서 실행 중인 사용자 SYSDIG_BPF_PROBE는 Command Line에서 환경 변수를 지정하는 표준 sysdig Container를 실행할 수 있으며 아래의 예제와 같이 사용할 수 있습니다.
•
Command
docker run -i -t --name sysdig --privileged -v /var/run/docker.sock:/host/var/run/docker.sock -v /dev:/host/dev -v /proc:/host/proc:ro -v /boot:/host/boot:ro -v /lib/modules:/host/lib/modules:ro -v /usr:/host/usr:ro --net=host -e SYSDIG_BPF_PROBE="" sysdig/sysdig
Bash
복사
Falco와 sysdig Monitor 및 sysdig secure aguent에 동일한 control flow을 사용할 수 있습니다. SYSDIG_BPF_PROBE 환경 변수를 전달하는 해당 Container를 시작하기만 하면 됩니다.
Falco
특정 문제 해결 사용 사례 외에 CNCF 샌드박스에 기부된 Falco 프로젝트는 이제 eBPF를 사용할 수 있습니다. Falco는 현재 Linux, Container 및 Kubernetes ecosystem에서 eBPF로 구동되는 Container를 위한 유일한 주요 보안 및 행동 활동 Monitering Tool입니다.
또한 Falco는 대표적으로 아래의 3가지 장점을 가지고 있습니다.
1.
컨테이너 보안 강화
유연한 규칙 엔진을 사용하면 모든 유형의 Host 또는 Container 동작을 설명할 수 있습니다.
2.
즉각적인 경고를 통해 위험 감소
정책 위반 경고에 즉시 대응하고 대응 workflows 내에서 Falco를 통합할 수 있습니다.
3.
최신 탐지 규칙 활용
Falco 즉시 사용 가능한 규칙은 악의적인 활동 및 CVE Exploit에 대해 경고합니다.











